Security in MCP: Protecting Your AI Workflows
It’s 3 AM. Your phone buzzes. The automated monitoring system detected something: someone just accessed your production MCP server and ran a database query that shouldn’t be possible. They extracted customer data. Your MCP tool, designed to help your AI assistant query business metrics, just became a data breach.
This isn’t hypothetical. MCP servers execute real code with real permissions. They access databases, file systems, APIs, and sensitive business logic. And by default, many MCP implementations have minimal security.
If you’re building MCP servers for production use, security isn’t optional. It’s the foundation.
In this guide, you’ll learn how to build secure MCP servers from the ground up. We’ll cover authentication, authorization, input validation, rate limiting, and production deployment best practices. By the end, you’ll understand how to protect your AI workflows from common vulnerabilities and build production-ready MCP servers.

Prerequisites
Before diving into MCP security, you should have:
Required Knowledge:
- Python fundamentals (async/await, decorators, type hints)
- MCP basics (servers, tools, resources) - Check our MCP Getting Started Guide
- Basic security concepts (authentication vs. authorization, encryption basics)
Tools You’ll Need:
- Python 3.10 or higher
- Code editor (VS Code recommended)
- Understanding of environment variables and configuration
Helpful But Not Required:
- Experience with FastAPI or similar frameworks
- Basic understanding of JWT tokens
- Knowledge of OAuth 2.0 flows
If you’re new to MCP, start with our MCP series introduction to understand the fundamentals before tackling security.
Understanding the MCP Security Model
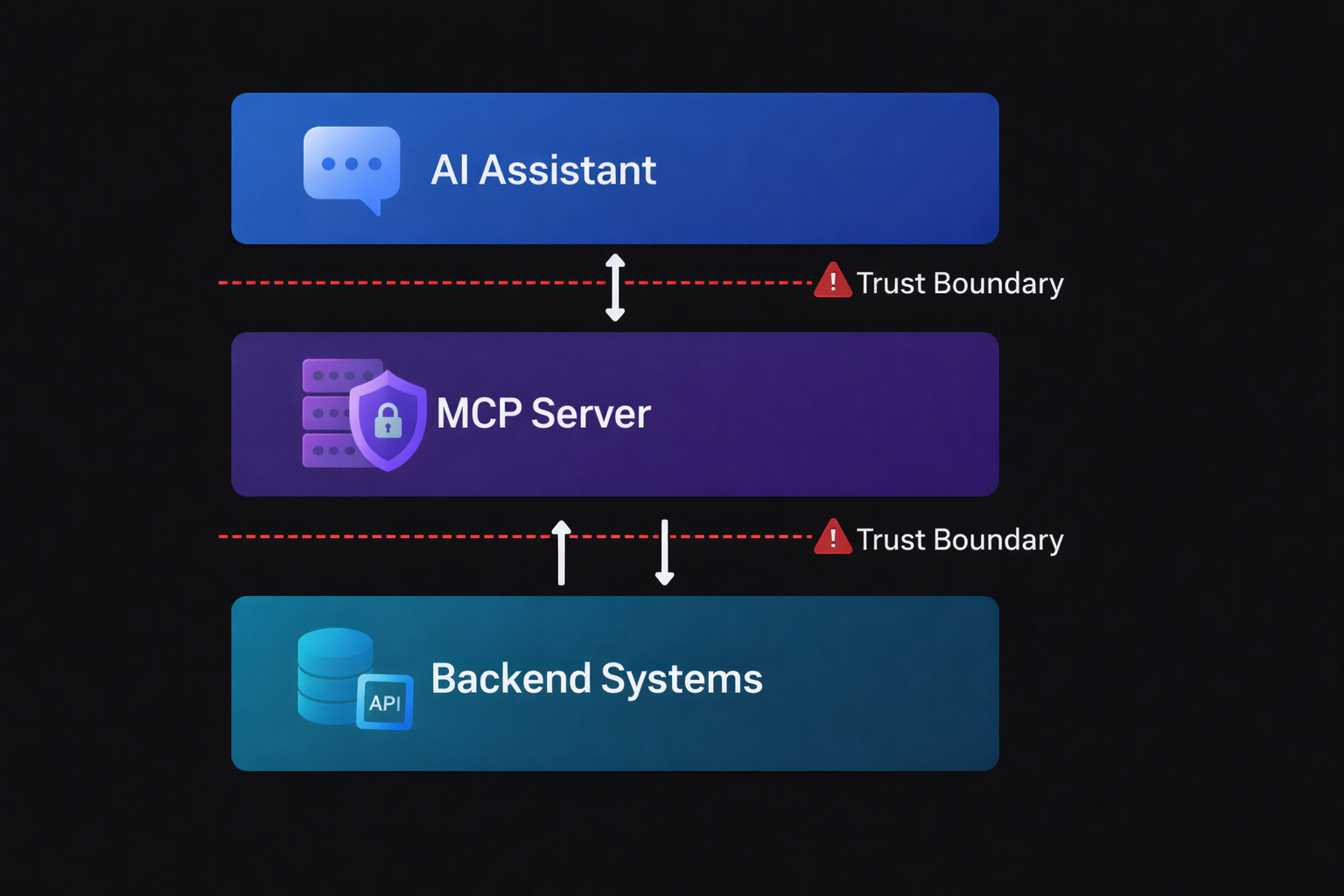
MCP servers sit at a critical intersection: they bridge AI assistants with real-world systems. This creates unique security challenges.
The Trust Boundary Problem
In a typical MCP setup, you have three actors:
- The AI Assistant (Claude, GPT-4, etc.) - Makes requests based on user prompts
- The MCP Server - Executes tools and accesses resources
- The Backend Systems (databases, APIs, file systems) - The actual data and functionality
The security challenge: The AI doesn’t understand security. It makes requests based on user prompts, which could be malicious, accidental, or poorly formed. Your MCP server is the gatekeeper.
The MCP Threat Model
What are you protecting against?
External Threats:
- Unauthorized access - Users without proper credentials accessing your MCP server
- Malicious prompts - Users crafting prompts to exploit tool vulnerabilities
- Data exfiltration - Extracting sensitive data through seemingly innocent queries
- Resource exhaustion - Overwhelming your server with requests (DoS attacks)
Internal Threats:
- Accidental damage - Well-meaning users running destructive operations
- Privilege escalation - Users accessing tools beyond their permission level
- Data leakage - Sensitive information appearing in logs or error messages
- Tool misuse - Using tools in unintended ways that compromise security
Security Layers
Effective MCP security requires multiple layers:
- Authentication - Who are you?
- Authorization - What are you allowed to do?
- Input Validation - Is this request safe?
- Rate Limiting - Are you making too many requests?
- Tool Execution Safety - Can this tool run safely?
- Audit Logging - What happened and when?
- Transport Security - Is the communication channel secure?
Each layer defends against different attacks. Remove one layer, and you create vulnerabilities.
BRAIN POWER
Why Multiple Layers Matter
Authentication alone isn’t enough. An authenticated user could still:
- Run SQL injection attacks through your database tool
- Overwhelm your server with thousands of requests
- Access resources they shouldn’t have permission for
- Execute commands that damage your system
Each security layer catches what the others miss. This is called “defense in depth.”
Authentication: Who’s Calling Your Server?
Authentication verifies identity. Before your MCP server does anything, it needs to know who’s making the request.
Method 1: API Key Authentication (Simple & Effective)
API keys are the simplest authentication method. Each client gets a unique key, and they include it with every request.
When to use API keys:
- Internal tools with limited users
- Development and testing environments
- Simple deployments where you control all clients
When NOT to use API keys:
- User-facing applications (use OAuth instead)
- Scenarios requiring fine-grained permissions
- When you need token expiration
Here’s a production-ready API key implementation:
import os
from typing import Optional
from mcp.server import Server
from mcp.types import Tool, TextContent
class AuthenticationError(Exception):
"""Raised when authentication fails"""
pass
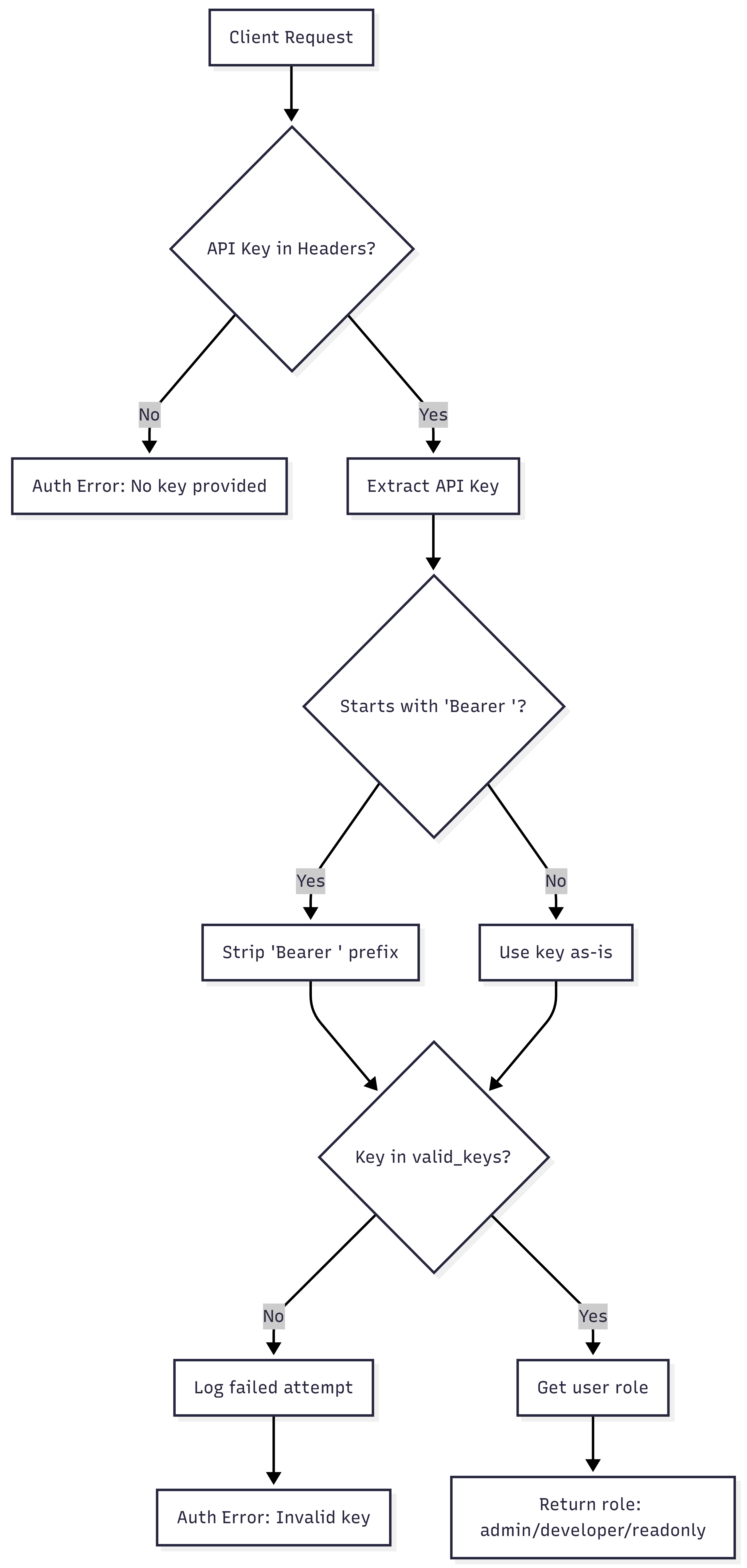
async def verify_api_key(headers: dict) -> str:
"""
Verify API key from request headers.
Returns the user's role (admin, readonly, etc.)
Raises AuthenticationError if key is invalid.
"""
# Extract API key from Authorization header
api_key = headers.get("authorization")
if not api_key:
raise AuthenticationError("No API key provided")
# Support "Bearer <key>" format
if api_key.startswith("Bearer "):
api_key = api_key[7:]
# Check against valid keys (stored in environment variables)
valid_keys = {
os.getenv("ADMIN_API_KEY"): "admin",
os.getenv("READONLY_API_KEY"): "readonly",
os.getenv("DEVELOPER_API_KEY"): "developer"
}
user_role = valid_keys.get(api_key)
if not user_role:
# Log failed authentication attempt
print(f"Failed authentication attempt with key: {api_key[:8]}...")
raise AuthenticationError("Invalid API key")
return user_role
# Example usage in MCP server
server = Server("secure-server")
@server.list_tools()
async def list_tools(context) -> list[Tool]:
# Verify authentication before listing tools
try:
role = await verify_api_key(context.request_headers)
print(f"Authenticated user with role: {role}")
except AuthenticationError as e:
raise ValueError(f"Authentication required: {e}")
# Return tools based on role (covered in Authorization section)
return get_tools_for_role(role)
Key points:
- API keys stored in environment variables (never hardcode)
- Support “Bearer” token format for compatibility
- Return user role for authorization decisions
- Log failed attempts for security monitoring
- Use descriptive error messages (but don’t leak information)
Method 2: JWT Tokens (Stateless & Scalable)
JWT (JSON Web Tokens) provides stateless authentication with expiration and claims.
When to use JWT:
- Multiserver deployments (no shared session state needed)
- Need token expiration
- Want to embed user information in the token
- Building a service that other services authenticate against
Here’s a JWT implementation:
import jwt
import os
from datetime import datetime, timedelta
from typing import Dict, Any
SECRET_KEY = os.getenv("JWT_SECRET_KEY")
ALGORITHM = "HS256"
TOKEN_EXPIRATION_HOURS = 24
def create_jwt_token(user_id: str, role: str, permissions: list[str]) -> str:
"""
Create a JWT token with user information and expiration.
"""
expiration = datetime.utcnow() + timedelta(hours=TOKEN_EXPIRATION_HOURS)
payload = {
"user_id": user_id,
"role": role,
"permissions": permissions,
"exp": expiration,
"iat": datetime.utcnow()
}
token = jwt.encode(payload, SECRET_KEY, algorithm=ALGORITHM)
return token
async def verify_jwt_token(token: str) -> Dict[str, Any]:
"""
Verify JWT token and return payload.
Raises AuthenticationError if token is invalid or expired.
"""
try:
payload = jwt.decode(token, SECRET_KEY, algorithms=[ALGORITHM])
return payload
except jwt.ExpiredSignatureError:
raise AuthenticationError("Token has expired")
except jwt.InvalidTokenError:
raise AuthenticationError("Invalid token")
# Example usage in MCP server
@server.list_tools()
async def list_tools(context) -> list[Tool]:
auth_header = context.request_headers.get("authorization", "")
if not auth_header.startswith("Bearer "):
raise ValueError("Missing or invalid authorization header")
token = auth_header[7:]
try:
payload = await verify_jwt_token(token)
user_id = payload["user_id"]
role = payload["role"]
permissions = payload["permissions"]
print(f"Authenticated user {user_id} with role {role}")
# Return tools based on permissions
return get_tools_for_permissions(permissions)
except AuthenticationError as e:
raise ValueError(f"Authentication failed: {e}")
Advantages of JWT:
- No server-side session storage needed
- Tokens contain user information (no database lookup)
- Built-in expiration
- Can be verified without calling an authentication service
Security considerations:
- Store SECRET_KEY securely (environment variable, secrets manager)
- Use strong algorithms (HS256 minimum, RS256 better for distributed systems)
- Set reasonable expiration times (hours, not months)
- Implement a token refresh mechanism for long-lived sessions
- Never store sensitive data in JWT payload (it’s base64 encoded, not encrypted)
Method 3: OAuth 2.0 (Enterprise Grade)
OAuth 2.0 is the industry standard for delegated authorization.
When to use OAuth:
- User-facing applications
- Need to integrate with existing identity providers (Google, Microsoft, Okta)
- Enterprise environments with SSO requirements
- Third-party integrations
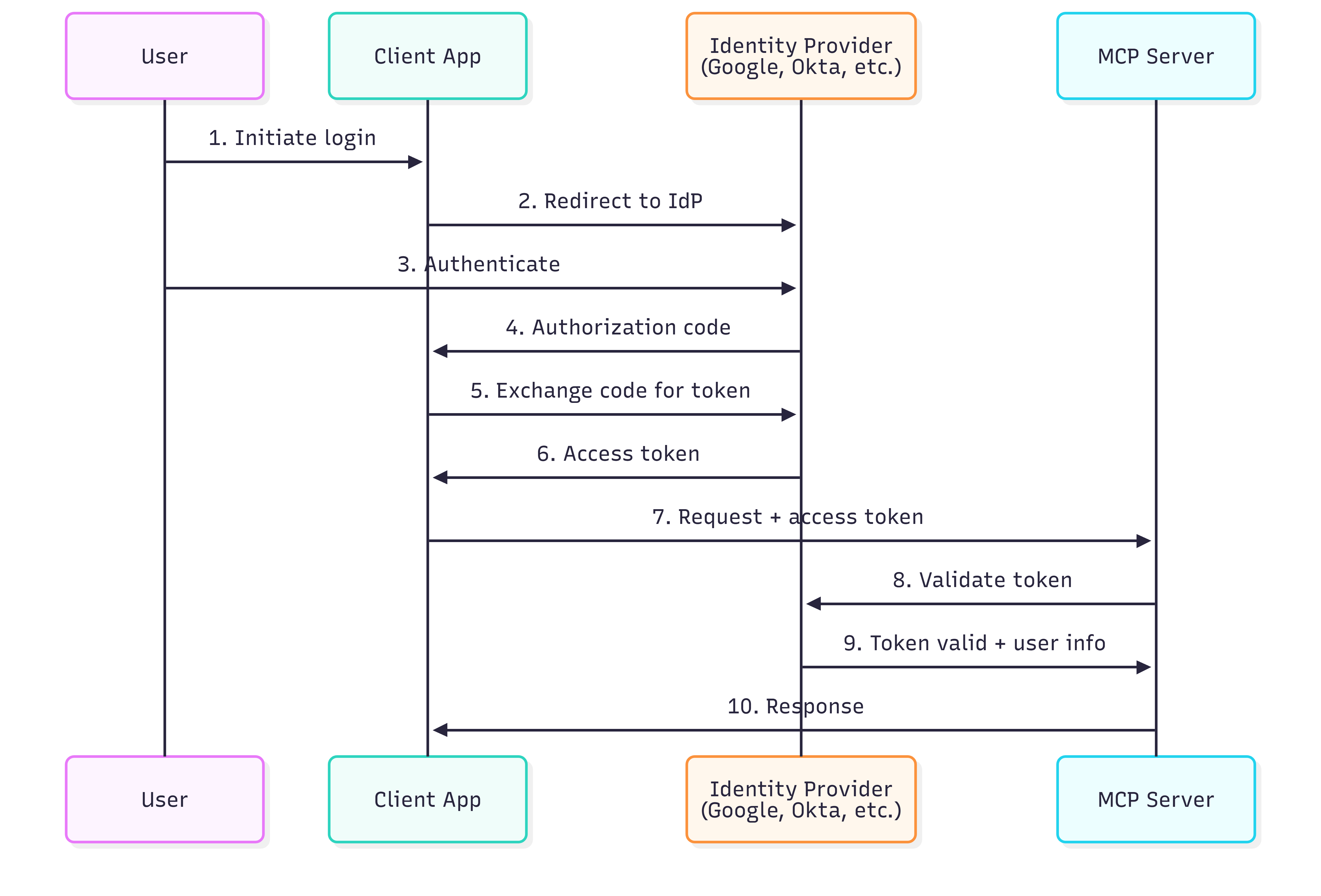
OAuth flow for MCP:
- User initiates OAuth flow (redirected to identity provider)
- User authenticates with identity provider
- Identity provider returns authorization code
- Your server exchanges code for an access token
- Client includes access token in MCP requests
- Your server validates token with identity provider
from authlib.integrations.starlette_client import OAuth
import os
oauth = OAuth()
oauth.register(
name='google',
client_id=os.getenv('GOOGLE_CLIENT_ID'),
client_secret=os.getenv('GOOGLE_CLIENT_SECRET'),
server_metadata_url='https://accounts.google.com/.well-known/openid-configuration',
client_kwargs={'scope': 'openid email profile'}
)
async def verify_oauth_token(token: str) -> Dict[str, Any]:
"""
Verify OAuth access token with identity provider.
"""
# Verify token with Google's token info endpoint
async with httpx.AsyncClient() as client:
response = await client.get(
'https://oauth2.googleapis.com/tokeninfo',
params={'access_token': token}
)
if response.status_code != 200:
raise AuthenticationError("Invalid OAuth token")
token_info = response.json()
# Verify token is for your app
if token_info.get('aud') != os.getenv('GOOGLE_CLIENT_ID'):
raise AuthenticationError("Token not issued for this application")
return {
"user_id": token_info.get("sub"),
"email": token_info.get("email"),
"name": token_info.get("name")
}
OAuth benefits:
- Users don’t create new passwords
- Centralized access control
- Works with enterprise identity providers
- Industry-standard security practices
WATCH OUT
Authentication Alone Isn’t Enough
Just because a user is authenticated doesn’t mean they should access everything. That’s where authorization comes in.
An authenticated user could still:
- Access tools they shouldn’t use
- Run dangerous commands
- View sensitive data they don’t have permission for
Always combine authentication with authorization (next section).
Authorization: What Can They Do?
Authentication tells you WHO the user is. Authorization determines WHAT they can do.
Role-Based Access Control (RBAC)
RBAC assigns permissions based on user roles. It’s simple, scalable, and easy to understand.
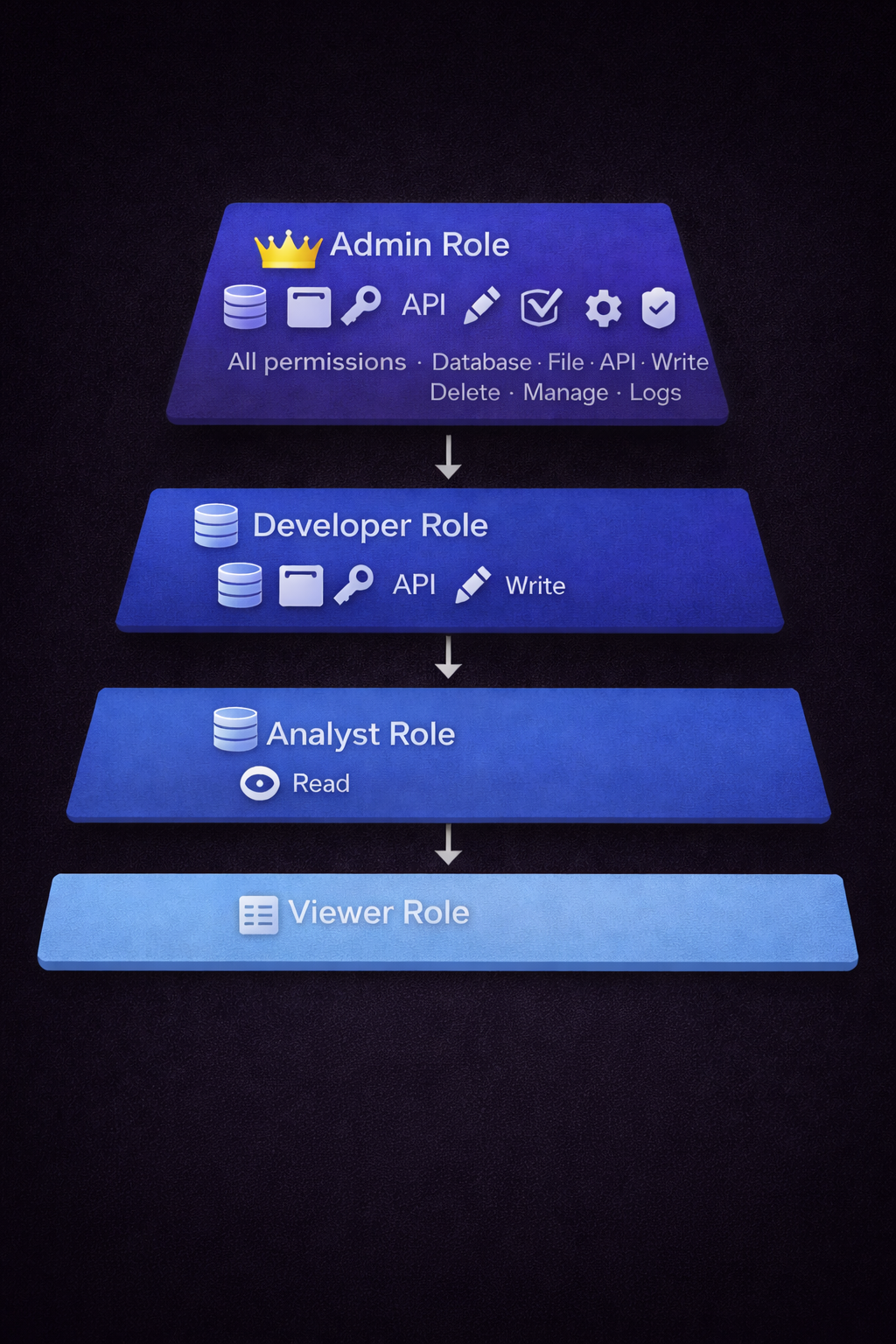
Common MCP roles:
- Admin - Full access to all tools and resources
- Developer - Read/write access to development resources
- Analyst - Read-only access to query tools
- Viewer - Can list resources but not execute tools
Here’s a production RBAC implementation:
from enum import Enum
from typing import Set, List
from functools import wraps
class Role(str, Enum):
ADMIN = "admin"
DEVELOPER = "developer"
ANALYST = "analyst"
VIEWER = "viewer"
class Permission(str, Enum):
# Tool permissions
EXECUTE_DATABASE_QUERY = "execute_database_query"
EXECUTE_FILE_OPERATIONS = "execute_file_operations"
EXECUTE_API_CALLS = "execute_api_calls"
# Resource permissions
READ_SENSITIVE_DATA = "read_sensitive_data"
WRITE_DATA = "write_data"
DELETE_DATA = "delete_data"
# Administrative permissions
MANAGE_USERS = "manage_users"
VIEW_LOGS = "view_logs"
# Define role permissions
ROLE_PERMISSIONS: dict[Role, Set[Permission]] = {
Role.ADMIN: {
Permission.EXECUTE_DATABASE_QUERY,
Permission.EXECUTE_FILE_OPERATIONS,
Permission.EXECUTE_API_CALLS,
Permission.READ_SENSITIVE_DATA,
Permission.WRITE_DATA,
Permission.DELETE_DATA,
Permission.MANAGE_USERS,
Permission.VIEW_LOGS,
},
Role.DEVELOPER: {
Permission.EXECUTE_DATABASE_QUERY,
Permission.EXECUTE_FILE_OPERATIONS,
Permission.EXECUTE_API_CALLS,
Permission.WRITE_DATA,
},
Role.ANALYST: {
Permission.EXECUTE_DATABASE_QUERY,
Permission.READ_SENSITIVE_DATA,
},
Role.VIEWER: {
# Viewers can only list resources, no tool execution
}
}
def has_permission(role: Role, permission: Permission) -> bool:
"""Check if a role has a specific permission."""
return permission in ROLE_PERMISSIONS.get(role, set())
def require_permission(permission: Permission):
"""
Decorator to enforce permission checks on tool functions.
"""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
# Extract role from context (set during authentication)
context = kwargs.get('context')
if not context:
raise ValueError("Missing context in tool call")
role = context.get('user_role')
if not role:
raise ValueError("User role not set (authentication required)")
# Check permission
if not has_permission(Role(role), permission):
raise PermissionError(
f"Role '{role}' does not have permission '{permission}'"
)
# Permission granted - execute tool
return await func(*args, **kwargs)
return wrapper
return decorator
# Example usage in MCP tools
@server.call_tool()
@require_permission(Permission.EXECUTE_DATABASE_QUERY)
async def query_database(arguments: dict, context: dict) -> List[TextContent]:
"""
Execute a database query (requires EXECUTE_DATABASE_QUERY permission).
"""
query = arguments.get("query")
# Execute query safely (covered in Input Validation section)
results = await execute_safe_query(query)
return [TextContent(
type="text",
text=f"Query results:\n{results}"
)]
@server.call_tool()
@require_permission(Permission.DELETE_DATA)
async def delete_records(arguments: dict, context: dict) -> List[TextContent]:
"""
Delete database records (requires DELETE_DATA permission).
Only admins can delete data.
"""
table = arguments.get("table")
condition = arguments.get("condition")
# Validate and execute deletion
count = await safe_delete(table, condition)
return [TextContent(
type="text",
text=f"Deleted {count} records from {table}"
)]
Key RBAC principles:
- Define roles based on job functions, not individuals
- Use permissions for granular control
- Apply principle of least privilege (give minimum permissions needed)
- Make authorization checks explicit and auditable
- Fail closed (deny by default, allow explicitly)
Dynamic Authorization
Sometimes you need more context than just a role. For example:
- Users can only query their own data
- Developers can only access development environments
- Analysts can query up to 1000 rows, admins unlimited
async def check_query_authorization(
user_id: str,
role: Role,
query: str,
table: str
) -> None:
"""
Advanced authorization that considers user, role, and query context.
"""
# Analysts can only query their own data
if role == Role.ANALYST:
if not query_includes_user_filter(query, user_id):
raise PermissionError(
"Analysts can only query their own data. "
f"Add: WHERE user_id = '{user_id}'"
)
# Check row limit based on role
row_limits = {
Role.ADMIN: None, # No limit
Role.DEVELOPER: 10000,
Role.ANALYST: 1000,
Role.VIEWER: 0 # Can't query at all
}
limit = row_limits.get(role)
if limit is not None:
if not query_has_limit(query) or extract_limit(query) > limit:
raise PermissionError(
f"Role '{role}' is limited to {limit} rows. "
f"Add: LIMIT {limit}"
)
# Check table access (some tables are restricted)
restricted_tables = {
"users": {Role.ADMIN},
"financial_data": {Role.ADMIN, Role.ANALYST},
"audit_logs": {Role.ADMIN}
}
if table in restricted_tables:
allowed_roles = restricted_tables[table]
if role not in allowed_roles:
raise PermissionError(
f"Table '{table}' requires one of these roles: {allowed_roles}"
)
THERE ARE NO DUMB QUESTIONS
Q: Should I use roles or permissions?
A: Both. Roles group permissions for easier management. Permissions provide granular control. Assign permissions to roles, then assign roles to users.
Q: How many roles should I have?
A: Start with three to five roles based on actual job functions. Too many roles become unmanageable. Too few and you end up granting excessive permissions.
Q: Can a user have multiple roles?
A: Technically, yes, but it gets complicated. Better to create a new role that combines the necessary permissions.
Input Validation: Protecting Against Attacks
Your MCP tools accept user input through the AI assistant. That input could be malicious, malformed, or dangerous.
Never trust input. Even from authenticated, authorized users.
SQL Injection Prevention
SQL injection is one of the most common and dangerous vulnerabilities. It happens when user input is directly inserted into SQL queries.
Vulnerable code (NEVER do this):
# DANGEROUS - DO NOT USE
async def unsafe_query(table: str, condition: str):
query = f"SELECT * FROM {table} WHERE {condition}"
return await database.execute(query)
# Attacker can inject:
# table = "users; DROP TABLE users; --"
# condition = "1=1 OR '1'='1"
Secure code (ALWAYS do this):
import sqlite3
from typing import List, Any
async def safe_query(table: str, user_id: str, limit: int = 100) -> List[dict]:
"""
Execute a safe database query using parameterized statements.
"""
# Validate table name against whitelist (no parameterization for table names)
allowed_tables = {"users", "products", "orders", "analytics"}
if table not in allowed_tables:
raise ValueError(
f"Invalid table '{table}'. Allowed: {allowed_tables}"
)
# Validate limit
if not isinstance(limit, int) or limit < 1 or limit > 10000:
raise ValueError("Limit must be between 1 and 10000")
# Use parameterized query (prevents SQL injection)
query = f"SELECT * FROM {table} WHERE user_id = ? LIMIT ?"
# Parameters are safely escaped by the database driver
results = await database.fetch_all(query, [user_id, limit])
return results
SQL injection protection checklist:
- DO: Use parameterized queries (? placeholders) for ALL user input
- DO: Whitelist table and column names (can’t be parameterized)
- DO: Validate data types (integers as integers, not strings)
- DO: Use ORM libraries when possible (they handle parameterization)
- DON’T: Concatenate user input into SQL queries
- DON’T: Use f-strings or string formatting for SQL

Command Injection Prevention
If your MCP server executes system commands, you’re at risk of command injection.
Vulnerable code:
# DANGEROUS - DO NOT USE
import subprocess
async def unsafe_file_operation(filename: str):
result = subprocess.run(f"cat {filename}", shell=True, capture_output=True)
return result.stdout.decode()
# Attacker can inject:
# filename = "file.txt; rm -rf / --no-preserve-root"
Secure code:
import subprocess
import shlex
from pathlib import Path
async def safe_file_read(filename: str, base_dir: str = "/safe/directory") -> str:
"""
Safely read a file without command injection risk.
"""
# Validate filename (no path traversal)
if '..' in filename or filename.startswith('/'):
raise ValueError("Invalid filename (no path traversal allowed)")
# Construct full path
base_path = Path(base_dir)
file_path = base_path / filename
# Verify path is within allowed directory (prevents ../../../etc/passwd)
if not str(file_path.resolve()).startswith(str(base_path.resolve())):
raise ValueError("Path traversal detected")
# Check file exists and is a file (not directory, symlink, etc.)
if not file_path.is_file():
raise ValueError(f"File not found: {filename}")
# Read file directly (no subprocess needed)
with open(file_path, 'r') as f:
return f.read()
# If you MUST use subprocess, do it safely:
async def safe_subprocess_example(filename: str):
"""
Execute command safely using list format (not shell=True).
"""
# Validate filename first
validated_path = await validate_file_path(filename)
# Use list format (prevents injection)
result = subprocess.run(
["cat", str(validated_path)], # List, not string
shell=False, # CRITICAL: Never use shell=True with user input
capture_output=True,
timeout=5 # Prevent hanging
)
return result.stdout.decode()
Command injection protection:
- Avoid subprocess whenever possible (use Python libraries)
- If a subprocess is needed, use a list format, never shell=True
- Validate all input paths for traversal attempts
- Use Path.resolve() to prevent symbolic link tricks
- Set timeouts to prevent hanging processes
- NEVER pass user input to shell=True
- NEVER construct shell commands with f-strings
Path Traversal Prevention
Path traversal attacks try to access files outside the intended directory.
Examples of path traversal attacks:
../../../../etc/passwd..\..\..\..\windows\system32\config\sam- Symbolic links pointing outside safe directories
Secure path validation:
from pathlib import Path
from typing import Optional
class PathValidator:
"""Validates file paths to prevent traversal attacks."""
def __init__(self, base_directory: str):
self.base_dir = Path(base_directory).resolve()
def validate_path(self, user_path: str) -> Path:
"""
Validate a user-provided path against traversal attacks.
Returns absolute Path if valid.
Raises ValueError if path is unsafe.
"""
# Check for obviously malicious patterns
if '..' in user_path:
raise ValueError("Path traversal detected: '..' not allowed")
if user_path.startswith('/') or user_path.startswith('\\'):
raise ValueError("Absolute paths not allowed")
# Construct full path
full_path = (self.base_dir / user_path).resolve()
# Critical check: ensure resolved path is within base directory
if not str(full_path).startswith(str(self.base_dir)):
raise ValueError(
f"Path traversal detected: {user_path} resolves outside base directory"
)
# Check for symbolic links (optional, depending on security requirements)
if full_path.is_symlink():
# Resolve symlink and check again
target = full_path.readlink().resolve()
if not str(target).startswith(str(self.base_dir)):
raise ValueError("Symbolic link points outside base directory")
return full_path
# Usage in MCP tool
validator = PathValidator("/safe/user/files")
@server.call_tool()
@require_permission(Permission.EXECUTE_FILE_OPERATIONS)
async def read_user_file(arguments: dict, context: dict) -> List[TextContent]:
"""Safely read a file from user directory."""
filename = arguments.get("filename")
try:
# Validate path
safe_path = validator.validate_path(filename)
# Verify it's a regular file (not device, socket, etc.)
if not safe_path.is_file():
raise ValueError("Not a regular file")
# Check file size (prevent memory exhaustion)
file_size = safe_path.stat().st_size
max_size = 10 * 1024 * 1024 # 10 MB
if file_size > max_size:
raise ValueError(f"File too large: {file_size} bytes (max {max_size})")
# Read file
content = safe_path.read_text()
return [TextContent(type="text", text=content)]
except ValueError as e:
return [TextContent(type="text", text=f"Error: {e}")]
Pydantic Schema Validation
Use Pydantic to validate input structure and types automatically.
from pydantic import BaseModel, Field, validator
from typing import Optional
class DatabaseQueryInput(BaseModel):
"""Validated input for database queries."""
table: str = Field(..., description="Table name to query")
user_id: str = Field(..., description="User ID to filter by")
limit: int = Field(default=100, ge=1, le=10000, description="Result limit")
columns: Optional[list[str]] = Field(default=None, description="Columns to select")
@validator('table')
def validate_table(cls, v):
allowed = {"users", "products", "orders", "analytics"}
if v not in allowed:
raise ValueError(f"Invalid table. Allowed: {allowed}")
return v
@validator('columns')
def validate_columns(cls, v):
if v is None:
return None
allowed = {"id", "name", "email", "created_at", "status"}
invalid = set(v) - allowed
if invalid:
raise ValueError(f"Invalid columns: {invalid}")
return v
# Usage in tool
@server.call_tool()
async def query_database_validated(arguments: dict, context: dict):
"""Query database with automatic input validation."""
try:
# Pydantic validates automatically
validated = DatabaseQueryInput(**arguments)
# Safe to use - all inputs validated
results = await safe_query(
table=validated.table,
user_id=validated.user_id,
limit=validated.limit,
columns=validated.columns
)
return [TextContent(type="text", text=str(results))]
except ValidationError as e:
# Pydantic provides detailed error messages
return [TextContent(
type="text",
text=f"Invalid input: {e.json()}"
)]
Pydantic benefits:
- Automatic type validation
- Range and pattern checking
- Custom validators for business logic
- Clear error messages
- Self-documenting input schemas
WATCH OUT
Common Input Validation Mistakes
- Validating too late - Validate at the entry point, not deep in your code
- Trusting authenticated users - Even admins can make mistakes or be compromised
- Blacklisting instead of whitelisting - Allow known-good, don’t block known-bad
- Forgetting edge cases - Empty strings, null bytes, Unicode tricks
- Not validating file uploads - Check a file type, size, content
Input validation is your first line of defense. Do it thoroughly.
Rate Limiting: Preventing Abuse
Rate limiting protects your server from being overwhelmed by requests, whether from legitimate users making mistakes or malicious actors attempting denial-of-service.
Why Rate Limiting Matters for MCP
MCP tools often trigger expensive operations:
- Database queries
- API calls to external services
- File system operations
- Complex computations
Without rate limiting, a user (or compromised account) could:
- Overwhelm your database with thousands of queries
- Exhaust API quotas in minutes
- Generate massive infrastructure costs
- Make your server unavailable for other users
Token Bucket Algorithm
The token bucket is a simple, effective rate-limiting algorithm.
How it works:
- Each user has a “bucket” that holds tokens
- Tokens regenerate at a fixed rate (e.g., 10 per minute)
- Each request consumes a token
- If no tokens available, request is denied
- Tokens accumulate up to a maximum (burst capacity)
import asyncio
import time
from collections import defaultdict
from dataclasses import dataclass
from typing import Dict
@dataclass
class TokenBucket:
"""Token bucket for rate limiting."""
capacity: int # Maximum tokens
tokens: float # Current tokens
fill_rate: float # Tokens per second
last_update: float # Last update timestamp
def consume(self, tokens: int = 1) -> bool:
"""
Try to consume tokens.
Returns True if successful, False if rate limit exceeded.
"""
# Refill tokens based on time elapsed
now = time.time()
elapsed = now - self.last_update
self.tokens = min(
self.capacity,
self.tokens + (elapsed * self.fill_rate)
)
self.last_update = now
# Try to consume
if self.tokens >= tokens:
self.tokens -= tokens
return True
return False
class RateLimiter:
"""Rate limiter using token bucket algorithm."""
def __init__(
self,
requests_per_minute: int = 60,
burst_capacity: int = 100
):
self.buckets: Dict[str, TokenBucket] = {}
self.requests_per_minute = requests_per_minute
self.burst_capacity = burst_capacity
self.fill_rate = requests_per_minute / 60.0 # tokens per second
def get_bucket(self, user_id: str) -> TokenBucket:
"""Get or create token bucket for user."""
if user_id not in self.buckets:
self.buckets[user_id] = TokenBucket(
capacity=self.burst_capacity,
tokens=self.burst_capacity,
fill_rate=self.fill_rate,
last_update=time.time()
)
return self.buckets[user_id]
def check_rate_limit(self, user_id: str, cost: int = 1) -> bool:
"""
Check if request is allowed under rate limit.
Args:
user_id: Unique user identifier
cost: Token cost of this request (default 1)
Returns:
True if allowed, False if rate limited
"""
bucket = self.get_bucket(user_id)
return bucket.consume(cost)
def get_wait_time(self, user_id: str, cost: int = 1) -> float:
"""
Get time in seconds until request would be allowed.
"""
bucket = self.get_bucket(user_id)
if bucket.tokens >= cost:
return 0.0
tokens_needed = cost - bucket.tokens
return tokens_needed / self.fill_rate
# Create rate limiter instance
rate_limiter = RateLimiter(
requests_per_minute=60, # 60 requests per minute
burst_capacity=100 # Can burst up to 100 requests
)
# Usage in MCP server
@server.call_tool()
async def rate_limited_tool(arguments: dict, context: dict):
"""Example tool with rate limiting."""
user_id = context.get("user_id")
# Check rate limit
if not rate_limiter.check_rate_limit(user_id):
wait_time = rate_limiter.get_wait_time(user_id)
return [TextContent(
type="text",
text=f"Rate limit exceeded. Try again in {wait_time:.1f} seconds."
)]
# Request allowed - proceed with tool execution
result = await expensive_operation(arguments)
return [TextContent(type="text", text=result)]
Different Rate Limits for Different Operations
Not all operations should have the same rate limit. Database queries are more expensive than reading cached data.
class TieredRateLimiter:
"""Rate limiter with different limits for different operation types."""
def __init__(self):
self.limiters = {
"database_query": RateLimiter(requests_per_minute=30, burst_capacity=50),
"api_call": RateLimiter(requests_per_minute=100, burst_capacity=150),
"file_read": RateLimiter(requests_per_minute=200, burst_capacity=300),
"expensive_computation": RateLimiter(requests_per_minute=10, burst_capacity=15)
}
def check_limit(self, user_id: str, operation_type: str, cost: int = 1) -> bool:
"""Check rate limit for specific operation type."""
limiter = self.limiters.get(operation_type)
if not limiter:
raise ValueError(f"Unknown operation type: {operation_type}")
return limiter.check_rate_limit(user_id, cost)
# Usage
tiered_limiter = TieredRateLimiter()
@server.call_tool()
async def query_database(arguments: dict, context: dict):
user_id = context.get("user_id")
# Use database query rate limit
if not tiered_limiter.check_limit(user_id, "database_query"):
return [TextContent(type="text", text="Rate limit exceeded for database queries")]
# Continue with query...
Role-Based Rate Limits
Different user roles can have different rate limits.
RATE_LIMITS_BY_ROLE = {
Role.ADMIN: {
"requests_per_minute": 1000,
"burst_capacity": 2000
},
Role.DEVELOPER: {
"requests_per_minute": 200,
"burst_capacity": 400
},
Role.ANALYST: {
"requests_per_minute": 100,
"burst_capacity": 200
},
Role.VIEWER: {
"requests_per_minute": 30,
"burst_capacity": 50
}
}
def get_rate_limiter_for_role(role: Role) -> RateLimiter:
"""Get rate limiter configured for user role."""
limits = RATE_LIMITS_BY_ROLE[role]
return RateLimiter(
requests_per_minute=limits["requests_per_minute"],
burst_capacity=limits["burst_capacity"]
)
BRAIN POWER
Rate Limiting Best Practices
- Set limits based on actual usage patterns - Monitor your server and set limits 2-3x normal usage
- Allow bursts - Burst capacity handles legitimate spikes without frustrating users
- Return clear error messages - Tell users how long to wait
- Different limits for different roles - Admins need higher limits than viewers
- Different limits for different operations - Expensive operations get stricter limits
- Consider global limits too - Protect your infrastructure with server-wide limits
- Log rate limit violations - Could indicate attacks or misconfigured clients
Tool Execution Safety: Sandboxing and Resource Limits
Even with authentication, authorization, and input validation, tools can still be dangerous. What if a legitimate query runs for hours? What if it consumes all memory?
Timeouts for Tool Execution
Never let a tool run indefinitely.
import asyncio
from functools import wraps
def timeout(seconds: int):
"""Decorator to add timeout to async functions."""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
try:
return await asyncio.wait_for(
func(*args, **kwargs),
timeout=seconds
)
except asyncio.TimeoutError:
raise TimeoutError(
f"Operation timed out after {seconds} seconds"
)
return wrapper
return decorator
# Usage
@server.call_tool()
@timeout(30) # 30 second timeout
async def slow_operation(arguments: dict, context: dict):
"""Operation with automatic timeout."""
result = await potentially_slow_query(arguments)
return [TextContent(type="text", text=result)]
Memory Limits
Protect against operations that consume excessive memory.
import resource
def set_memory_limit(max_memory_mb: int):
"""Set memory limit for current process."""
max_memory_bytes = max_memory_mb * 1024 * 1024
resource.setrlimit(
resource.RLIMIT_AS,
(max_memory_bytes, max_memory_bytes)
)
# Set 512 MB memory limit
set_memory_limit(512)
Resource Monitoring
Monitor resource usage during tool execution.
import psutil
import os
async def check_resource_usage():
"""Check current resource usage."""
process = psutil.Process(os.getpid())
memory_info = process.memory_info()
memory_mb = memory_info.rss / 1024 / 1024
cpu_percent = process.cpu_percent(interval=0.1)
return {
"memory_mb": round(memory_mb, 2),
"cpu_percent": round(cpu_percent, 2)
}
@server.call_tool()
async def resource_intensive_operation(arguments: dict, context: dict):
"""Monitor resources during operation."""
start_resources = await check_resource_usage()
try:
result = await expensive_operation(arguments)
finally:
end_resources = await check_resource_usage()
memory_used = end_resources["memory_mb"] - start_resources["memory_mb"]
# Log resource usage
print(f"Operation used {memory_used:.2f} MB memory")
print(f"CPU usage: {end_resources['cpu_percent']}%")
return [TextContent(type="text", text=result)]
THERE ARE NO DUMB QUESTIONS
Q: What’s a reasonable timeout for MCP tools?
A: Depends on the operation. Simple queries: 5-10 seconds. Complex analytics: 30-60 seconds. Anything longer should probably be an async job, not a synchronous tool.
Q: Will memory limits crash my server?
A: Memory limits kill the process that exceeds them. Use process isolation or containerization to prevent affecting other parts of your system.
Sensitive Data Handling: Protecting Private Information
MCP tools often access sensitive data: user information, financial records, API keys, health data. This data needs special protection.
Never Log Sensitive Data
Bad logging:
# DANGEROUS - logs sensitive data
print(f"User query: {user_email} password: {password}")
print(f"API response: {credit_card_number}")
Safe logging:
def sanitize_for_logging(data: dict) -> dict:
"""Remove sensitive fields from data before logging."""
sensitive_fields = {
"password", "api_key", "secret", "token",
"credit_card", "ssn", "email", "phone"
}
sanitized = {}
for key, value in data.items():
if key.lower() in sensitive_fields:
sanitized[key] = "***REDACTED***"
elif isinstance(value, dict):
sanitized[key] = sanitize_for_logging(value)
else:
sanitized[key] = value
return sanitized
# Usage
user_data = {"email": "user@example.com", "name": "John", "password": "secret123"}
print(f"User data: {sanitize_for_logging(user_data)}")
# Output: User data: {'email': '***REDACTED***', 'name': 'John', 'password': '***REDACTED***'}
Encrypt Sensitive Data at Rest
from cryptography.fernet import Fernet
import os
class EncryptionService:
"""Encrypt/decrypt sensitive data."""
def __init__(self):
# Load encryption key from environment (NEVER hardcode)
key = os.getenv("ENCRYPTION_KEY")
if not key:
raise ValueError("ENCRYPTION_KEY not set")
self.cipher = Fernet(key.encode())
def encrypt(self, data: str) -> str:
"""Encrypt string data."""
encrypted = self.cipher.encrypt(data.encode())
return encrypted.decode()
def decrypt(self, encrypted_data: str) -> str:
"""Decrypt string data."""
decrypted = self.cipher.decrypt(encrypted_data.encode())
return decrypted.decode()
# Usage
encryption = EncryptionService()
# Encrypt before storing
api_key = "sk-1234567890abcdef"
encrypted_key = encryption.encrypt(api_key)
await database.store("api_keys", encrypted_key)
# Decrypt when needed
stored_key = await database.fetch("api_keys")
decrypted_key = encryption.decrypt(stored_key)
PII Detection and Masking
import re
class PIIDetector:
"""Detect and mask personally identifiable information."""
@staticmethod
def mask_email(text: str) -> str:
"""Mask email addresses."""
return re.sub(
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
'[EMAIL]',
text
)
@staticmethod
def mask_phone(text: str) -> str:
"""Mask phone numbers."""
return re.sub(
r'\b\d{3}[-.]?\d{3}[-.]?\d{4}\b',
'[PHONE]',
text
)
@staticmethod
def mask_ssn(text: str) -> str:
"""Mask social security numbers."""
return re.sub(
r'\b\d{3}-\d{2}-\d{4}\b',
'[SSN]',
text
)
@classmethod
def mask_all_pii(cls, text: str) -> str:
"""Mask all common PII types."""
text = cls.mask_email(text)
text = cls.mask_phone(text)
text = cls.mask_ssn(text)
return text
# Usage before logging or returning to AI
user_message = "Contact me at john@example.com or 555-123-4567"
safe_message = PIIDetector.mask_all_pii(user_message)
print(safe_message)
# Output: "Contact me at [EMAIL] or [PHONE]"
Transport Security: Securing the Communication Channel
All this security means nothing if attackers can intercept your communications.
Always Use HTTPS/TLS
For production MCP servers:
- Use TLS 1.2 or higher
- Use strong cipher suites
- Renew certificates before expiration
- Use trusted certificate authorities
import ssl
from aiohttp import web
# Create SSL context
ssl_context = ssl.create_default_context(ssl.Purpose.CLIENT_AUTH)
ssl_context.load_cert_chain('path/to/cert.pem', 'path/to/key.pem')
# Run server with TLS
web.run_app(app, ssl_context=ssl_context, port=443)
WebSocket Authentication
If using WebSocket transport for MCP:
async def websocket_handler(request):
"""Authenticate WebSocket connections."""
ws = web.WebSocketResponse()
await ws.prepare(request)
# First message must be authentication
try:
auth_msg = await asyncio.wait_for(ws.receive_json(), timeout=5)
token = auth_msg.get("token")
# Verify token
user_info = await verify_jwt_token(token)
# Authentication successful - proceed with MCP communication
async for msg in ws:
# Handle MCP messages
await handle_mcp_message(msg, user_info)
except asyncio.TimeoutError:
await ws.close(code=1008, message="Authentication timeout")
except AuthenticationError:
await ws.close(code=1008, message="Authentication failed")
return ws
Error Handling and Audit Logging
Secure error handling and comprehensive logging are critical for security.
Safe Error Messages
Never expose internal details in error messages.
Bad error handling:
# DANGEROUS - exposes internal details
try:
result = database.query(f"SELECT * FROM users WHERE id = {user_id}")
except Exception as e:
return f"Database error: {str(e)}"
# Might return: "Table 'users' doesn't exist in database 'production_db' at server 'db-master-01.internal'"
Good error handling:
try:
result = database.query_safe(user_id)
except DatabaseError as e:
# Log detailed error internally
logger.error(
"Database query failed",
extra={
"user_id": user_id,
"error": str(e),
"query": sanitize_query_for_logging(query)
}
)
# Return generic message to user
return "An error occurred while processing your request. Please try again or contact support."
Structured Audit Logging
Log all security-relevant events for audit and forensics.
import logging
import json
from datetime import datetime
from typing import Any, Dict
class AuditLogger:
"""Structured audit logging for security events."""
def __init__(self):
self.logger = logging.getLogger("audit")
# Configure logging to file
handler = logging.FileHandler("audit.log")
handler.setFormatter(logging.Formatter('%(message)s'))
self.logger.addHandler(handler)
self.logger.setLevel(logging.INFO)
def log_event(
self,
event_type: str,
user_id: str,
action: str,
resource: str,
success: bool,
metadata: Dict[str, Any] = None
):
"""Log a security event."""
event = {
"timestamp": datetime.utcnow().isoformat(),
"event_type": event_type,
"user_id": user_id,
"action": action,
"resource": resource,
"success": success,
"metadata": metadata or {}
}
self.logger.info(json.dumps(event))
# Global audit logger
audit_log = AuditLogger()
# Usage in tools
@server.call_tool()
async def delete_records(arguments: dict, context: dict):
user_id = context.get("user_id")
table = arguments.get("table")
try:
# Check authorization
if not has_permission(context.get("role"), Permission.DELETE_DATA):
audit_log.log_event(
event_type="authorization_failure",
user_id=user_id,
action="delete",
resource=table,
success=False,
metadata={"reason": "insufficient_permissions"}
)
raise PermissionError("Insufficient permissions")
# Execute deletion
count = await safe_delete(table, arguments.get("condition"))
# Log successful deletion
audit_log.log_event(
event_type="data_modification",
user_id=user_id,
action="delete",
resource=table,
success=True,
metadata={"records_deleted": count}
)
return [TextContent(type="text", text=f"Deleted {count} records")]
except Exception as e:
# Log failure
audit_log.log_event(
event_type="operation_failure",
user_id=user_id,
action="delete",
resource=table,
success=False,
metadata={"error": str(e)}
)
raise
What to log:
- LOG: Authentication attempts (success and failure)
- LOG: Authorization failures
- LOG: Data access and modifications
- LOG: Tool executions
- LOG: Rate limit violations
- LOG: Input validation failures
- LOG: Configuration changes
- SKIP: Sensitive data (passwords, API keys, PII)
Security Checklist: Common Vulnerabilities
Use this checklist to audit your MCP server security.
Authentication & Authorization
- All endpoints require authentication
- Authentication tokens expire appropriately
- Failed authentication attempts are logged
- Role-based access control implemented
- Permissions checked before all tool executions
- Authorization failures are logged
Input Validation
- All user input validated before use
- SQL queries use parameterization (no string concatenation)
- File paths validated against traversal attacks
- Whitelisting used (not blacklisting)
- Input size limits enforced
- Pydantic schemas validate tool arguments
Rate Limiting
- Rate limiting implemented for all tools
- Different limits for different operations
- Different limits for different roles
- Rate limit violations logged
- Clear error messages when the rate is limited
Data Protection
- Sensitive data encrypted at rest
- Sensitive data never logged
- PII detection and masking implemented
- Error messages don’t expose internal details
- Database credentials are not hardcoded
Tool Execution
- Timeouts set for all operations
- Resource limits (memory, CPU) configured
- Dangerous operations (delete, modify) require confirmation
- Tool execution is audited
Transport & Infrastructure
- HTTPS/TLS used in production
- TLS 1.2 or higher
- Environment variables for secrets
- Dependencies regularly updated
- Security patches applied promptly
Logging & Monitoring
- Audit log for security events
- Structured logging format
- Logs protected from tampering
- Monitoring for suspicious activity
- Alerts for repeated failures
Production Deployment Checklist
Before deploying your MCP server to production:
Pre-Deployment
- All secrets in environment variables (never in code)
- Authentication implemented and tested
- Authorization rules defined and tested
- Input validation comprehensive
- Rate limiting configured appropriately
- Audit logging enabled
- Error handling doesn’t leak information
- Dependencies updated to latest secure versions
- Code reviewed by a security-aware developer
Infrastructure
- TLS certificates installed and configured
- Firewall rules restrict access appropriately
- Server hardened (unnecessary services disabled)
- Monitoring and alerting configured
- Backup and disaster recovery plan
- Separate development/staging/production environments
Documentation
- Security policies documented
- User roles and permissions are documented
- Incident response plan created
- Contact information for security issues
- API documentation includes security requirements
Testing
- Penetration testing conducted
- Load testing completed
- Fail-over scenarios tested
- Rate limiting tested
- Authentication bypass attempts tested
- Input validation tested with malicious inputs
Real-World Example: Securing a Database Query Tool
Let’s bring everything together with a complete example of a secure database query tool.
Before (Insecure):
# INSECURE - DO NOT USE
@server.call_tool()
async def query_database_insecure(arguments: dict):
query = arguments.get("query")
result = await database.execute(query) # SQL injection!
return [TextContent(type="text", text=str(result))]
After (Secure):
from pydantic import BaseModel, Field, validator
from typing import List, Optional
import asyncio
class SecureDatabaseQueryInput(BaseModel):
"""Validated input for database queries."""
table: str = Field(..., description="Table to query")
columns: List[str] = Field(default=["*"], description="Columns to select")
conditions: Optional[dict] = Field(default=None, description="WHERE conditions")
limit: int = Field(default=100, ge=1, le=10000)
@validator('table')
def validate_table(cls, v):
allowed = {"users", "products", "orders", "analytics"}
if v not in allowed:
raise ValueError(f"Invalid table. Allowed: {allowed}")
return v
@validator('columns')
def validate_columns(cls, v):
if "*" in v:
return v
allowed = {"id", "name", "email", "created_at", "status", "total"}
invalid = set(v) - allowed
if invalid:
raise ValueError(f"Invalid columns: {invalid}")
return v
@server.call_tool()
@require_permission(Permission.EXECUTE_DATABASE_QUERY)
@timeout(30)
async def query_database_secure(arguments: dict, context: dict) -> List[TextContent]:
"""
Secure database query tool with full security controls.
"""
user_id = context.get("user_id")
role = Role(context.get("role"))
# 1. Rate limiting
if not rate_limiter.check_rate_limit(user_id, cost=1):
audit_log.log_event(
event_type="rate_limit_violation",
user_id=user_id,
action="query_database",
resource="database",
success=False
)
return [TextContent(
type="text",
text="Rate limit exceeded. Please wait before making more queries."
)]
try:
# 2. Input validation (Pydantic)
validated = SecureDatabaseQueryInput(**arguments)
# 3. Build parameterized query (SQL injection prevention)
columns_str = ", ".join(validated.columns) if validated.columns != ["*"] else "*"
query = f"SELECT {columns_str} FROM {validated.table}"
params = []
# Add WHERE clause if conditions provided
if validated.conditions:
where_parts = []
for column, value in validated.conditions.items():
where_parts.append(f"{column} = ?")
params.append(value)
query += " WHERE " + " AND ".join(where_parts)
# Add LIMIT
query += f" LIMIT ?"
params.append(validated.limit)
# 4. Authorization check (analysts can only query their own data)
if role == Role.ANALYST:
if "user_id" not in (validated.conditions or {}):
audit_log.log_event(
event_type="authorization_failure",
user_id=user_id,
action="query_database",
resource=validated.table,
success=False,
metadata={"reason": "analyst_must_filter_by_user_id"}
)
return [TextContent(
type="text",
text="Analysts must filter by their own user_id"
)]
# 5. Execute query safely
results = await database.fetch_all(query, params)
# 6. Mask PII before returning
safe_results = [
{k: PIIDetector.mask_all_pii(str(v)) for k, v in row.items()}
for row in results
]
# 7. Audit log
audit_log.log_event(
event_type="database_query",
user_id=user_id,
action="select",
resource=validated.table,
success=True,
metadata={
"row_count": len(results),
"limit": validated.limit
}
)
# 8. Return results
return [TextContent(
type="text",
text=f"Query returned {len(results)} rows:\n{json.dumps(safe_results, indent=2)}"
)]
except ValidationError as e:
# Input validation failed
return [TextContent(
type="text",
text=f"Invalid input: {e.errors()}"
)]
except PermissionError as e:
# Authorization failed
return [TextContent(
type="text",
text=f"Permission denied: {str(e)}"
)]
except asyncio.TimeoutError:
# Operation timed out
audit_log.log_event(
event_type="timeout",
user_id=user_id,
action="query_database",
resource=validated.table if 'validated' in locals() else "unknown",
success=False
)
return [TextContent(
type="text",
text="Query timed out. Try reducing the limit or simplifying conditions."
)]
except Exception as e:
# Unexpected error - log details internally, return generic message
logger.error(
f"Database query failed for user {user_id}",
exc_info=True,
extra=sanitize_for_logging({"arguments": arguments})
)
return [TextContent(
type="text",
text="An error occurred while processing your query. Please contact support if this persists."
)]
This example implements:
- Authentication (via
@require_permissiondecorator) - Authorization (role-based checks, analyst restrictions)
- Input validation (Pydantic schema)
- SQL injection prevention (parameterized queries)
- Rate limiting
- Timeouts
- PII masking
- Audit logging
- Safe error handling
What You’ve Learned
Security in MCP isn’t optional. In this guide, you’ve learned how to:
- Understand the MCP threat model and why security matters
- Implement authentication with API keys, JWT, and OAuth 2.0
- Build authorization systems with role-based access control
- Validate input to prevent SQL injection, command injection, and path traversal
- Apply rate limiting to prevent abuse and resource exhaustion
- Execute tools safely with timeouts and resource limits
- Protect sensitive data with encryption and PII detection
- Secure communications with HTTPS/TLS
- Handle errors safely without leaking information
- Implement audit logging for security monitoring
Security is a process, not a destination. As you build production MCP servers, regularly review this guide and update your security practices.
What’s Next
Continue your MCP mastery with these related guides:
- MCP Performance Optimization - Make your secure servers fast
- MCP Production Deployment - Deploy to production with confidence
- MCP Monitoring and Observability - Track security events and performance
Want to master MCP development? Check out our complete MCP series covering everything from basics to advanced production patterns. Start with Understanding MCP’s Role in JSON Communication.
Got questions about MCP security? Found a vulnerability in your implementation? We’re here to help. Reach out at studio.angry.shark@gmail.com.
Stay secure. Build confidently. Ship production-ready MCP servers.
About Angry Shark Studio
Angry Shark Studio is a professional Unity AR/VR development studio specializing in mobile multiplatform applications and AI solutions. Our team includes Unity Certified Expert Programmers with extensive experience in AR/VR development.
Related Articles
More Articles
Explore more insights on Unity AR/VR development, mobile apps, and emerging technologies.
View All Articles